Pranam Shetty
Rochester, NY
AI/ML Engineer. I build apps, finetune models and automate workflows to make life easier.
What I work with
Experience
AI Engineer Intern
May 2025 - Aug 2025
United States
Designed and implemented an end-to-end LLM benchmarking pipeline (featured by FT & CNBC) to evaluate model performance on financial tasks using rigorous frameworks and advanced prompting strategies.
ML Engineer Intern
June 2023 - Aug 2023
India
Built a real-time trading signal engine and multimodal feature pipeline (Ichimoku + FinBERT) on Kubernetes, improving throughput by 70% and prediction accuracy by 15% under volatile market conditions.
ML Research Intern
Sept 2021 - Nov 2021
India
Re-architected a distributed Spark ML pipeline reducing runtime by 75% and modernized risk assessment for 500K+ daily claims, enabling near-real-time scoring via Docker and Kubernetes.
SEO Analytics Intern
Feb 2020 - March 2020
India
Led the transition to digital advertising during the pandemic, optimizing Google/Facebook ad strategies and using analytics to drive higher conversions for educational courses.
Open Source Contributor
Jun 2024 - Now
Contributed to langchain, huggingface, raycast, and other open source projects
Projects
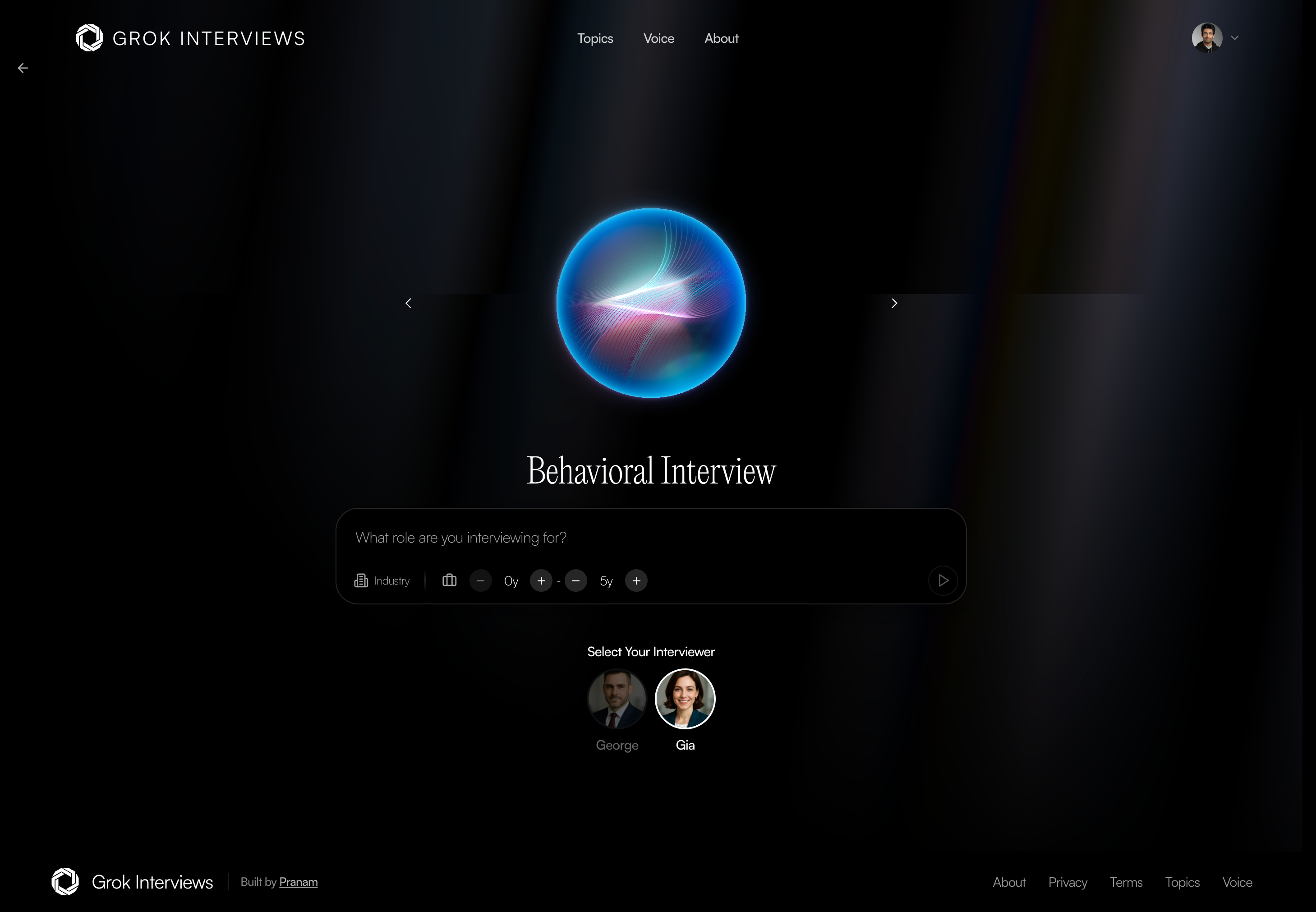
Grok Interviews
A comprehensive, enterprise-grade interview preparation platform featuring 3.6+ million curated resources and 81,499 technical questions across 5 major domains.
CodeClimax
A Chrome extension that celebrates your problem-solving successes with custom media. When you solve a LeetCode problem, the extension detects your success and displays a celebration overlay with your chosen media.
Blogs
2026-02-03
Agent-Oriented Planning: How to Make Multi-Agent AI Actually Work
Multi-agent AI systems promise to solve complex, real-world problems — but only if the team of specialized agents is properly coordinated…
2025-09-07
Attention Is Not All You Need. It's How You Need It.
Jet-Nemotron rethinks AI by using attention only when necessary, dramatically boosting speed and accuracy compared to traditional full-attention models.
2025-08-23
Are LLMs Needlessly Huge? Extreme Compression of LLMs using Quantum Inspired Tensor Networks
Presents a novel approach called CompactifAI by Multiverse Computing, which uses quantum-inspired tensor networks to drastically compress LLMs with minimal loss in accuracy.